After our user needs have been scoped and identified, and after exploring what type of data we can use, it’s time to start thinking about what technology should automated first patient contact be built on. When developing Artificial Intelligence solutions for primary care, what are our options?
As we mentioned in the previous article, the type of data, its amount and quality will pre-define the development tactics of the automated solution. So what technology is most suitable to deliver value in the long-run and cover the needs of both patients and healthcare professionals? There are several ways to create intelligent systems which could be broadly summarized by the 3 following options.
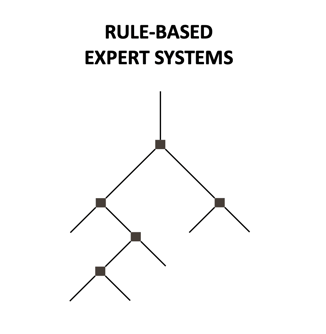
Rule-based expert systems
A rule-based expert system is the most tangible method to illustrate. Rule-based expert systems are based on an “if/then/else” linear structure of instructions. It is a clear, transparent and perfectly functioning method for tasks with limited complexity as literally every solution scenario needs to be described. Once a certain threshold of complexity is approached, there is a need of trade-off between granularity and ability to handle the number of scenarios, which often results in simplifications and generalisation and/or using a human being as a “secret sauce” for the functioning system. This type of algorithms has been broadly used in healthcare to accommodate a limited number of scenarios in decision-making support systems, to support humans in taking, among others, triage decisions. The main disadvantage of this system is that human beings cannot be taken out of the equation and replaced with a machine.
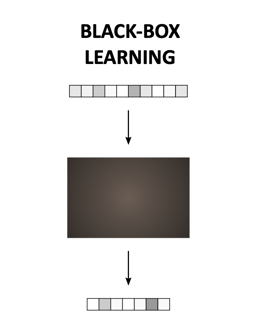
Black box
Black box algorithms are not big news in healthcare, especially thanks to radiology, where large sets of images have been processed to recognise patterns within a large number of images to e.g. distinguish between healthy and non-healthy tissue. A black box algorithm is fed with a large dataset, relevant to the task in question. It identifies the patterns and improves its accuracy with use, which is rather handy when datasets are so large and unclear that lead times of processing it by a human being make it to just a meaningless task. On the downside, the “why” behind each pattern formulation is impenetrable by humans, thus impossible to understand, motivate, and learn from. There are quite some situations where we are ready to take this deal of not seeing inside the “black box”, as the alternative is to not get any insight at all.
Probabilistic networks
There is a third approach that doesn’t get to be as much in the spotlight as the previous two. As opposed to the black box technologies, where the algorithm itself identifies the pattern, in a probabilistic network, for instance, us humans can provide the patterns and interpretations, at least at the outset. A probabilistic network is not necessarily fed with a huge amount of historical data but could rely on expert domain knowledge to considerably outperform “black box”-type algorithms trained on poor data. That knowledge needs to be translated in the right format and structured into appropriate nodes and connections for the algorithm to understand and process. The nodes in a probabilistic network represent variables of interest and the edges represent the association between them. In terms of primary care, symptoms and conditions would represent the nodes interlinked with different strength of relationships where relevant. Nodes and connections can be added, linked, and removed from the system to scale it up or down, and such a network is created to describe the problem rather than to give a concrete “recipe” of how to solve each potential scenario. This task is for the algorithm to figure out, as it can not only handle any number of scenarios and varying amounts of complexity but also account for the conclusions that it has come up with at every step.

Probabilistic networks allow for maximum transparency, as the input can be fully controlled, and they can provide a clear graphic representation which allows the users to efficiently document and evaluate the output as well as how this output was created. Handling our health in the fashion that it is done within primary care requires this sort of transparency, at least in the first steps.
Which approach works better for automating first patient contact?
For a simple task with a limited number of scenarios, rule-based expert systems are perfectly suitable; they are transparent, and the logic is easily accessible and controllable. However, automating first patient contact is neither limited nor simple – and this approach does not afford to scale up, nor does it support a sustainable integration with e.g. smart meters that already now pave their way into patient homes. In this spirit, we turn to the other two. A black box solution would potentially provide an adequate end-result, given high-quality input, but by their nature, these structures cannot deliver on uncompromisingly essential criteria of primary care processes: integration in the digi-physical workflow, transparency, and medical awareness context. Neither patients nor medical professionals would be able to motivate, evaluate or influence the result. The rules and logic are completely invisible to users which is not feasible in the context where a big bunch of rules is already known and explicitly described: What are the most typical symptoms of a specific condition.
Probabilistic network development has multiple advantages in scaling and transparency, and it stacks up to every presented usage need, as we discussed previously:
- It fulfils the medical awareness factor: Probabilistic networks allow us to insert expert domain knowledge and influence the nodes, connections and overall mapping of the network.
- We can influence what is displayed to the patient and ensure that they are met with relevant questions in a patient-friendly language.
- It provides full transparency and justification of the conclusions reached.
- It enables a clear graphic representation, which contributes to easier integration with the digi-physical workflow and even more important, the ability to explain the system to clinicians in terms of symptoms, conditions and the relationships between these.
Consequently, probabilistic network development is clearly highlighted as the most promising solution for the needs of primary patient contact. This way, both healthcare professionals and patients get valuable outcomes from the tool safely and reliably.
Since such developments are at a relatively early stage, healthcare professionals should be prepared to contribute with monitoring the flow and evaluating how reasonable and accurate the conclusion and potential referral of these new systems are. At the same time, the early benefits of the solutions that are still under construction and validation could be that healthcare professionals can prioritise easier, document patient cases more efficiently and signpost the patient flow effectively, with seamless integration with their workflow. As time goes by and the technology develops, cases will be handed over with high confidence levels to the algorithms. Patients’ lives are also to become simpler – they have another channel to healthcare, that answers to their needs of acknowledgement, trust and accessibility – whenever they need it and wherever they are, without putting an unbearable burden on the system.