
empowering healthcare. improving lives
Easing the healthcare burden
Experience the impact of AI-enabled triage and automation
free up resources
Right patient, right place, right away
Healthcare services are facing unprecedented challenges with increasing patient demand combined with workforce and capacity issues.
AI-enabled triage can help to better route patients at the first point of contact - enabling busy services to free up resource and work more efficiently.
market-leading AI-enabled triage
Meet Red Robin
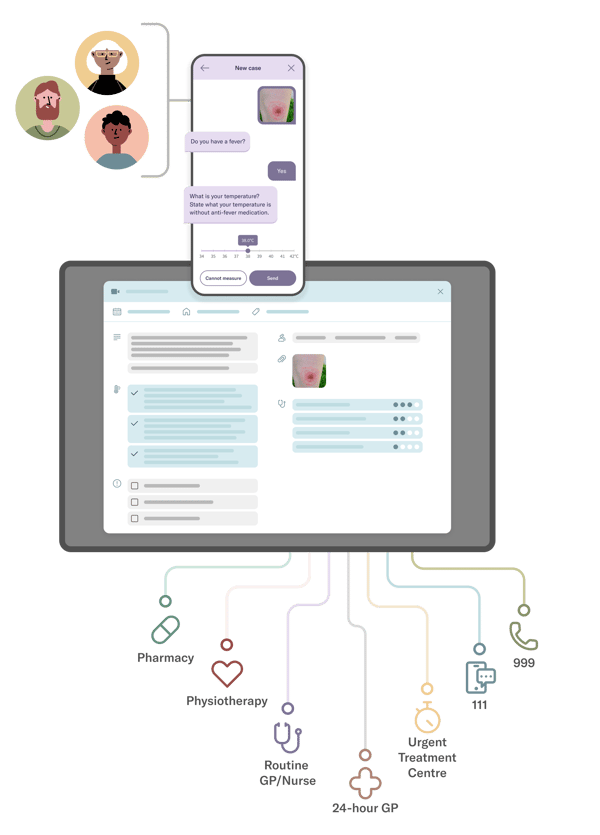
Comprehensive patient history
Red Robin takes a comprehensive patient history for new symptoms. Continuous analysis of patient inputs means patients are asked only relevant questions.
Urgent symptoms, at any point in the questioning sequence, trigger alerts telling patients to seek urgent care.
Reliable decision support
Patient history, images, potential diagnoses and urgency can be sent to a Smart Inbox for management and allocation.
Alternatively, cases can be automatically triaged to appropriate clinics, clinicians or team members.
Respond at first contact
Armed with full details of symptoms and urgency, HCPs can respond to patients at first contact - via messaging, email, video and forms.
Routing patients to the most appropriate HCP first time, improves patient experience and enables HCPs to make the most of their time.
healthcare partners
Who we work with

.png?width=600&height=141&name=nhs111%20black%20logo%20(1).png)













perspectives
Read our latest articles

Wakey Wellness – bringing health and wellbeing services to the children and young people of Wakefield
Read more
NHS staff recognise the potential of AI, but need assurance to confidently implement AI-enabled services
Read more