
Efter att ha analyserat användarnas behov och undersökt vilka datakällor som är lämpliga att använda vid automatisering av första linjens vård är det nu dags att börja fundera över val av teknik. Vilka olika modeller finns när man ska utveckla automatiserade lösningar baserade på artificiell intelligens för primärvården?
Som vi nämnde i föregående artikel, kommer typen av patientdata liksom dess mängd och kvalitet att ligga till grund för hur den automatiserade lösningen kan utvecklas. Vilken modell är då bäst lämpad att skapa långsiktigt värde och tillgodose både patienternas och vårdpersonalens behov? Det finns flera sätt att skapa automatiserade system och de kan delas in i följande övergripande kategorier.
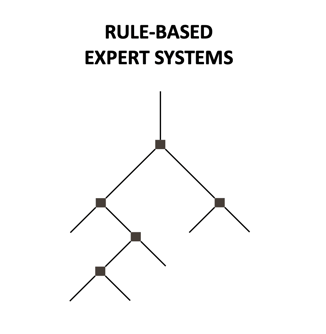
Regelbaserade expertsystem
Regelbaserade expertsystem bygger på den linjära instruktionsstrukturen ”if–then–else”. Metoden är tydlig, transparent och funktionell, men kan endast användas för uppgifter med begränsad komplexitet, eftersom varje lösningsscenario måste beskrivas på förhand. När en viss komplexitetströskel uppnås kan det vara nödvändigt att kompromissa mellan hur pass detaljerad man kan vara och förmågan att hantera antalet scenarier. Detta leder ofta till förenklingar och generaliseringar och/eller till att man använder sig av en människa som en “hemlig komponent” för att systemet ska fungera. Den här typen av algoritmer har använts i stor omfattning inom sjukvården för att hantera ett begränsat antal scenarier i olika slags beslutsstödsystem, bl.a. för triage. Den största nackdelen med detta system är att människan inte kan tas bort från ekvationen och risken är att man inte når önskad effekt.
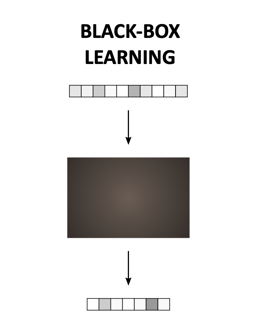
Black box
Black box-algoritmer är inget nytt inom hälso- och sjukvården. Till exempel har de använts inom radiologi, där stora mängder bilder har bearbetats för att kunna känna igen mönster, bl.a. i syfte att skilja mellan frisk och sjuk vävnad. Black Box-algoritmen matas med stora mängder data som är relevanta för en specifik uppgift. Den identifierar mönster och förbättrar noggrannheten i takt med användningen, vilket är praktiskt när datamängder är så stora att det vore meningslöst att låta en människa försöka bearbeta dem. Det finns dock en nackdel – orsaken till varför ett mönster uppstår kan inte tolkas av människan och är därmed omöjlig att förstå, motiveras och lära sig av. Dock kan vi i vissa fall vara beredda att godta bristen på transparens, särskilt om alternativet är att inte få någon insikt alls.
Sannolikhetsbaserade nätverk
Slutligen finns det en tredje modell som inte brukar få lika stor uppmärksamhet som de föregående två. I motsats till black box-modellen, där algoritmen själv identifierar mönstret, kan människan i ett sannolikhetsbaserat (även kallat probabilistiskt) nätverk få tillgång till mönster och tolkningar. Ett sannolikhetsbaserat nätverk matas inte nödvändigtvis med stora mängder historiska data, men kan använda sig av expertkunskaper inom ett område vilket gör det möjligt att prestera betydligt bättre än algoritmer av black box-typ som tränats på otillräckliga data. För att algoritmen ska kunna förstå och bearbeta kunskap måste den först omvandlas till rätt format och struktureras i lämpliga noder och sammanhang. Noderna i ett sannolikhetsbaserat nätverk representerar variabler av intresse och kopplingarna representerar sambandet mellan dessa. När det gäller primärvården skulle symtom och tillstånd representera noderna, som i relevanta fall sammankopplas med relationer av varierande styrka. Noder och kopplingar kan läggas till, länkas eller tas bort från systemet för att anpassa det, i syfte att beskriva problemet snarare än att ge ett konkret ”recept” på hur varje tänkbart scenario ska lösas. Det är algoritmens uppgift att komma fram till slutsatsen, dels genom att hantera otaliga scenarier och olika komplexitetsnivåer, dels genom att visa hur den dragit sina slutsatser i respektive steg.

Probabilistiska nätverk gör det möjligt att få maximal insyn i processen, eftersom inmatade data kan kontrolleras. De kan ta fram en tydlig grafisk framställning som gör att användare på ett effektivt sätt kan dokumentera och utvärdera utdata, samtidigt som det går att se hur dessa data skapades. Denna transparens är något som verkligen efterfrågas inom primärvården för att våga lämna över besluten åt automatiserade system.
Vilken modell fungerar bäst för automatisering av första linjens vård?
Vid en enkel uppgift med ett begränsat antal scenarier passar regelbaserade expertsystem perfekt. De är transparenta, och logiken är lättillgänglig och kontrollerbar. Automatisering av första linjens vård är dock varken begränsad eller enkel. Regelbaserade expertsystem tillåter inte heller skalning och går inte att integrera med t.ex. smarta verktyg och mätare för egenmonitorering.
Hur funkar det då med de andra två modellerna? En black box-modell skulle kunna ge ett tillfredsställande slutresultat om inmatade data håller hög kvalitet. Men den kan inte uppfylla de kriterier som krävs för primärvårdens processer – särskilt transparens och medvetenhet om det medicinska sammanhanget. Varken patienter eller sjukvårdspersonal har möjlighet att utvärdera eller påverka resultatet eftersom reglerna och logiken är helt obegripliga för användarna. Den fungerar inte heller väl i ett sammanhang där en mängd regler redan är kända och formulerade – vilka symtom som är mest typiska för en viss sjukdom eller diagnos.
Sannolikhetsbaserade nätverk däremot, har flera fördelar när det gäller storleksanpassning och transparens, och kan tillgodose användarnas behov, vilka vi diskuterade i en tidigare bloggpost.
Fördelarna är:
- De tillgodoser behovet av medicinsk kunskap; med sannolikhetsbaserade nätverk kan expertkunskaper inom området användas för att mappa noder och kopplingar i ett nätverk.
- Det går att påverka vad som visas för patienterna och se till att de möts av relevanta frågor ställda på ett naturligt språk.
- De erbjuder full insyn och kan förklara varför vissa slutsatser dragits.
- Det går att ta fram en grafisk framställning som underlättar integration med det digifysiska arbetsflödet, och framför allt – hjälper till att förklara hanteringen av symptom, tillstånd och relationerna mellan dessa för vårdgivaren.
Detta gör att sannolikhetsbaserade nätverk är den lösning som har störst potential för automatisering av första linjens vård, samtidigt som de öppnar upp nya möjligheter, bl.a. när det gäller personcentrerad vård och användning av medicinska mätverktyg i hemmet.
Både sjukvårdspersonal och patienter gynnas av denna lösning genom att modellen kan hantera resultat från ett verktyg på ett säkert och tillförlitligt sätt.
Eftersom utvecklingen av sannolikhetsbaserade nätverk befinner sig i ett relativt tidigt skede kan sjukvårdspersonal i nuläget behöva övervaka flödet och utvärdera hur pass rimliga och korrekta systemets slutsatser och hänvisningar är. Men redan idag finns ett antal vinster med modellen. Den kan hjälpa vårdpersonal att prioritera, hantera patientdokumentation smidigare och på ett mer effektivt sätt guida patienter rätt genom sömlös integration mellan olika flöden. Med tiden, när tekniken utvecklats ytterligare, kommer patientärenden i allt högre grad att tryggt kunna lämnas över till algoritmerna. Patienterna får ännu en kanal till vården som motsvarar deras behov av tillgänglighet, tillit och bekräftelse.
I nästa del av vår bloggserie kan du läsa om vad vårdpersonal tänker kring automatiserade lösningar.

